Physical Cluster replication
Opened a new market segment (10M+) for CRDB
Designed the user experience for Physical Cluster Replication (PCR), a disaster recovery protocol that enables customers with two data centers to survive a regional outage with minimal downtime.
PCR addressed a major adoption blocker for enterprise customers unable to support CockroachDB’s three-region deployment model, opening a new market segment (10M+) for CockroachDB Cloud.
I determined what PCR information was needed in the Cloud UI to support an API-first launch without disrupting existing workflows.
My role - Sr. Staff Product Designer leading technical UX strategy, workflow architecture, and end-to-end product design
Team - 1 UX researcher, 2 PMs, 2 engineering teams
Timeline - Jul - Nov 2025
Platform - CockroachDB Cloud
Status - Multiple customers using this feature in production
Challenge
CockroachDB had lost enterprise opportunities because some prospects operated across two data centers and could not support CockroachDB’s three-region deployment model.
PCR was introduced as an API-first release to address this gap. We intentionally avoided designing the full UI workflow upfront to validate real adoption patterns first and learn whether customers preferred managing replication programmatically or through the Cloud UI.
The challenge was determining what needed to exist in the UI to support the API launch safely and coherently, avoiding investment in workflows that might evolve significantly post-release.
Defining the UI scope
Because the PM came from a database infrastructure background and had limited experience designing customer-facing workflows, they relied heavily on me to define the UI implications.
I created a comprehensive journey map which helped the team visualize the long-term operational workflow, identify API-release blockers early, and align on a phased rollout strategy.
The PM and I quickly aligned on prioritizing the ongoing tasks over the one-time tasks in the UI:
Monitoring
Maintenance
Troubleshooting
Creation
Failover
This reframed the work from an API support task into a phased approach to future UI investment.
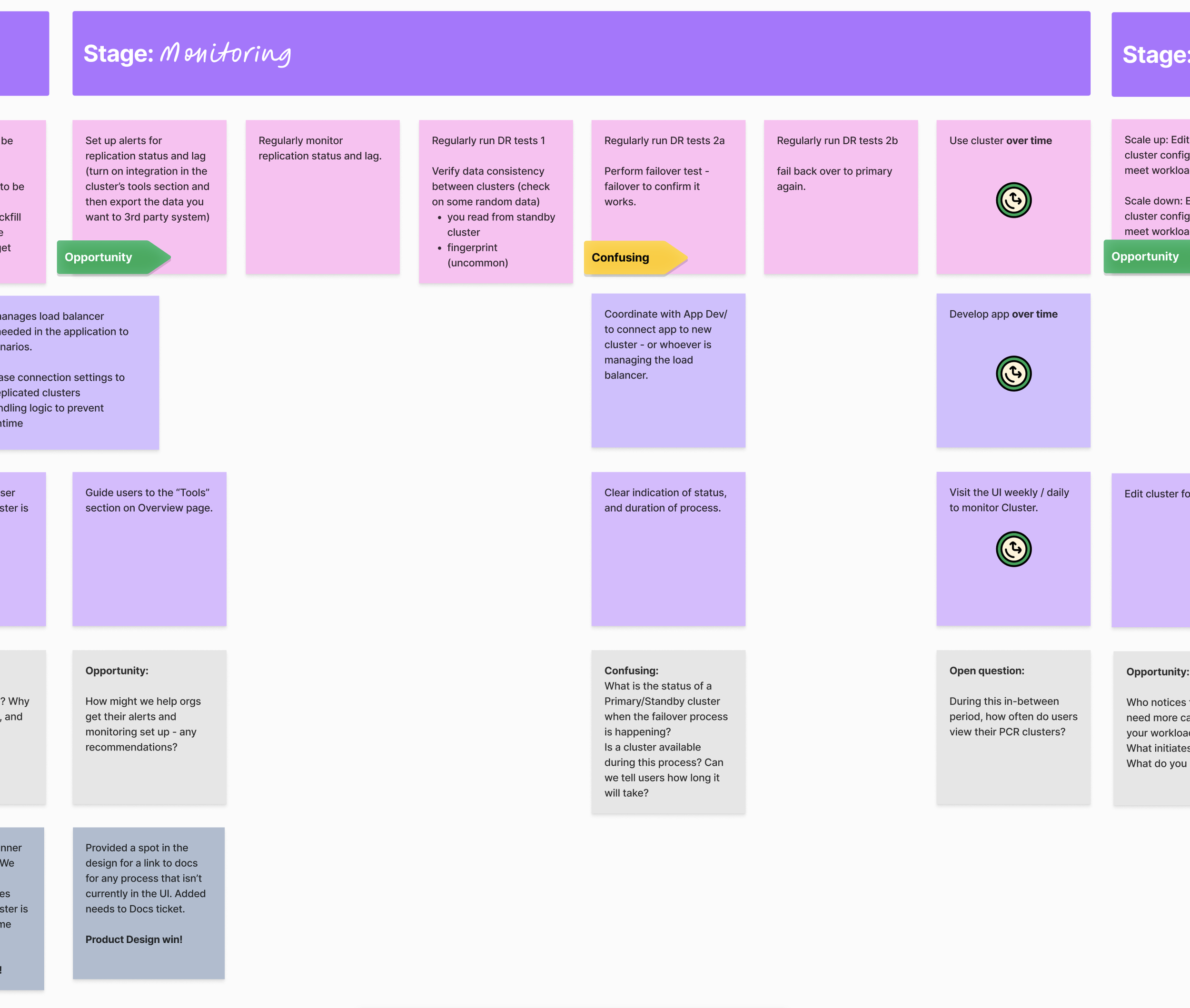
Monitoring section of User Journey map
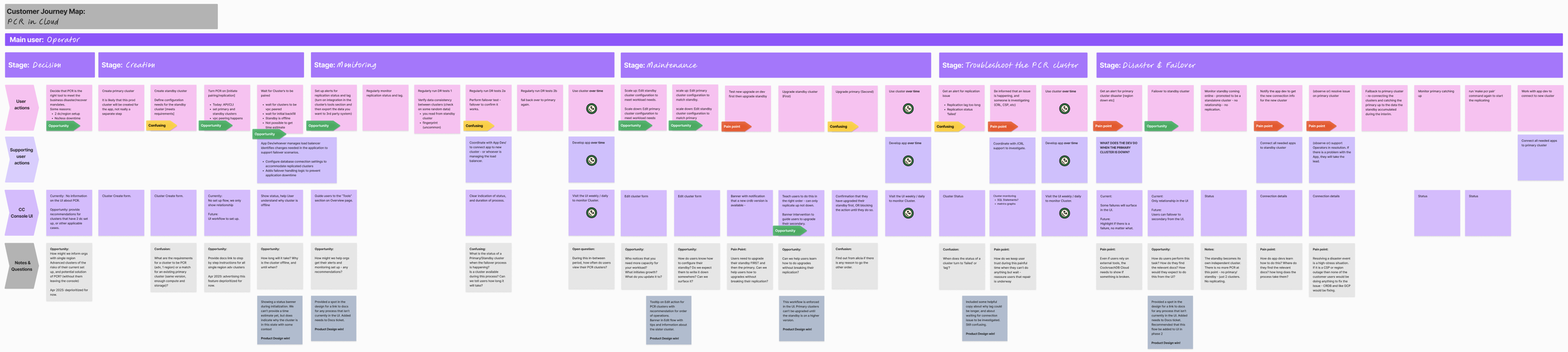
Full User Journey map
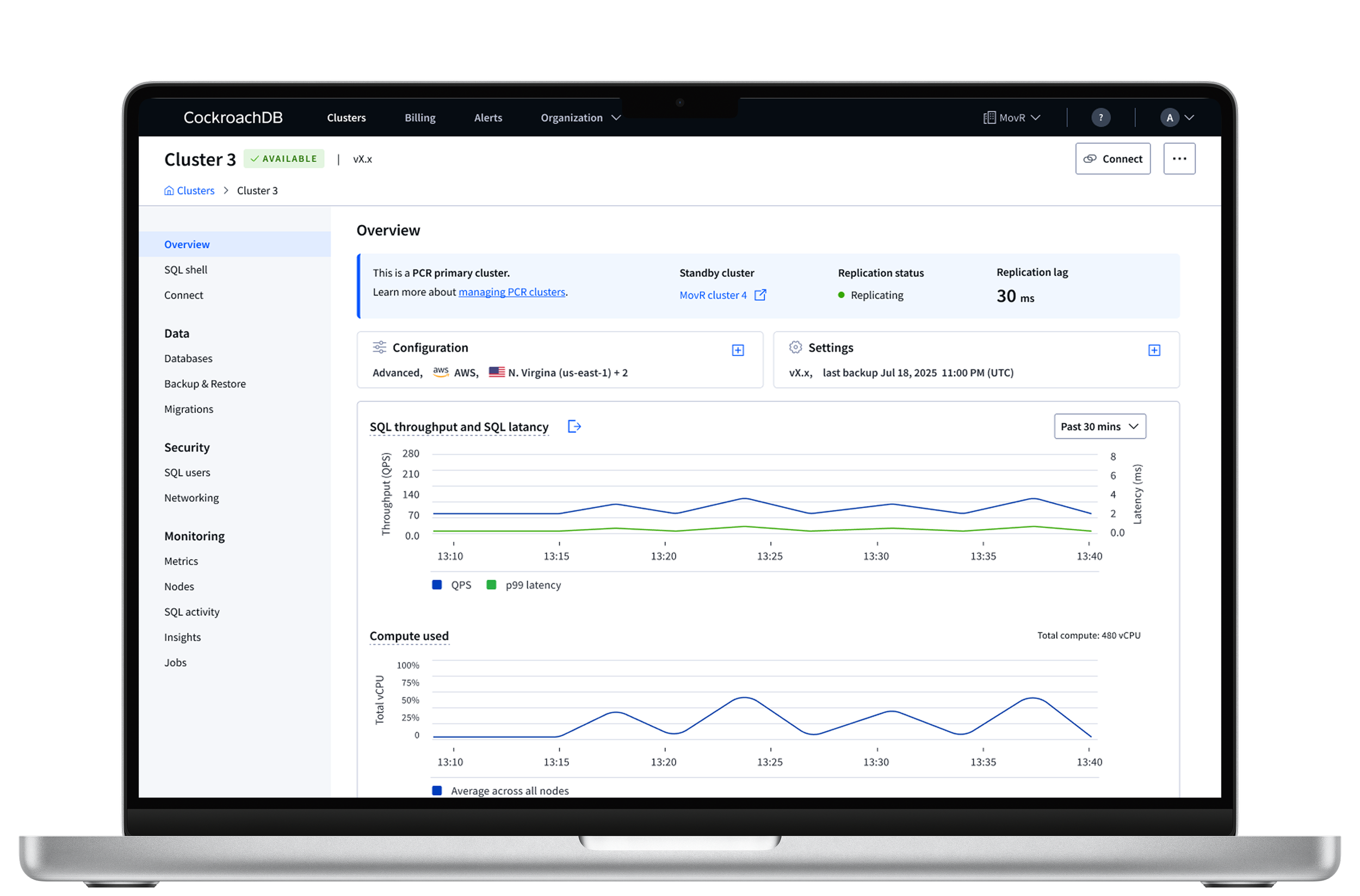
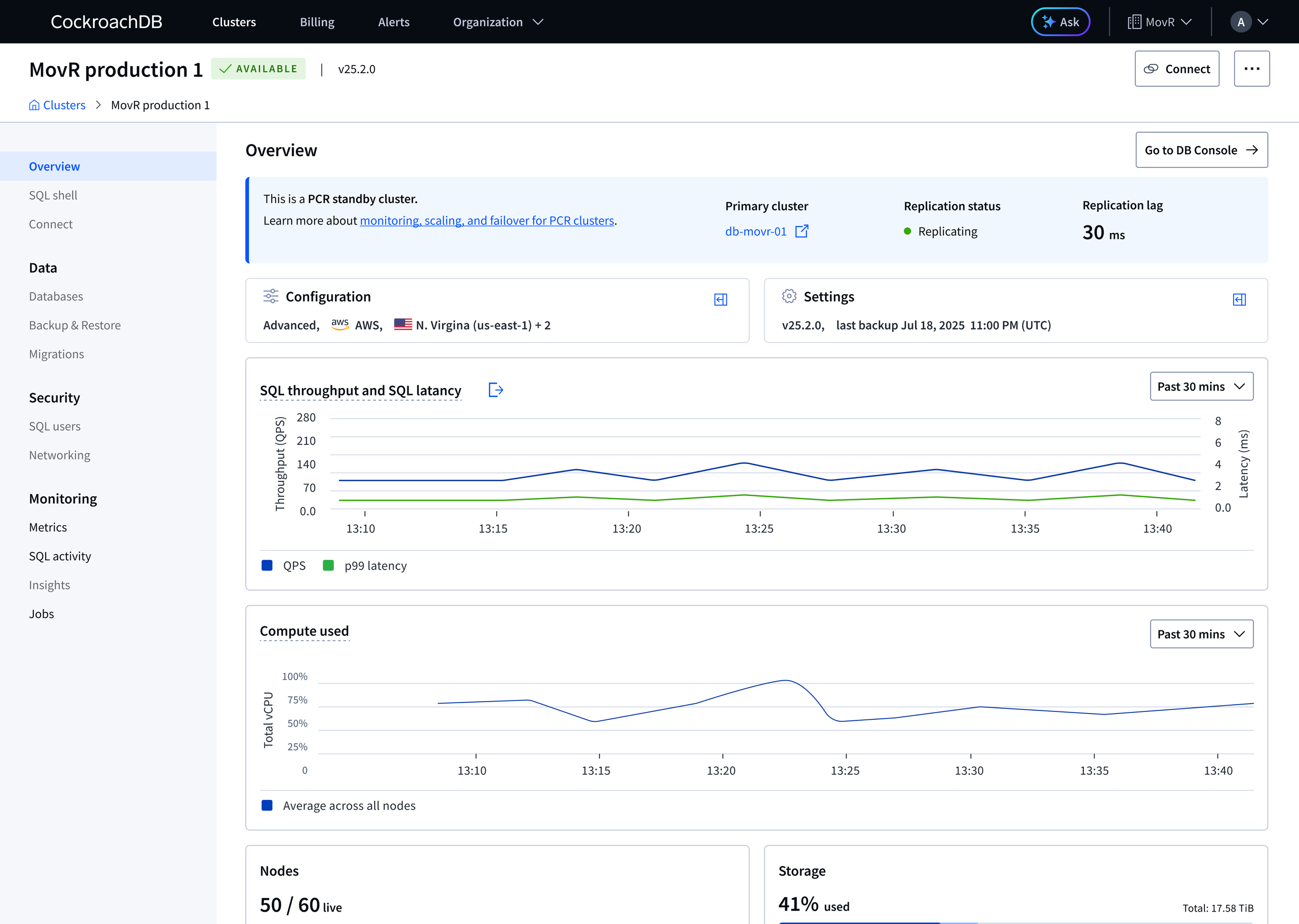
I identified early that the most important UX problem was making the relationship between the Primary and Standby clusters immediately understandable.
The standby cluster intentionally behaved differently from a standard cluster. Settings were locked, writes were disabled, and parts of the system were managed automatically. Without clear context, these constraints appeared broken or confusing.
This insight shaped the overall design direction. Rather than presenting the standby as an independent cluster, I designed the experience around the replication pair:
labeling the Primary and Standby throughout the UI
creating a navigational connection between paired clusters
surfacing replication health and status prominently
I validated two organizational models through user interviews:
a hierarchical model where paired clusters lived together
an independent model where clusters could exist separately
Users consistently understood the hierarchical model more easily and struggled to recognize the relationship in the independent version. I recommended requiring paired clusters to exist within the same folder structure.
However, because the team was still learning how customers would operationalize PCR, Product chose the more flexible independent model to avoid introducing constraints that could limit adoption. I revised the language, hierarchy, and layouts based on the research findings to clarify the relationship within those constraints.
Making the cluster relationship clear
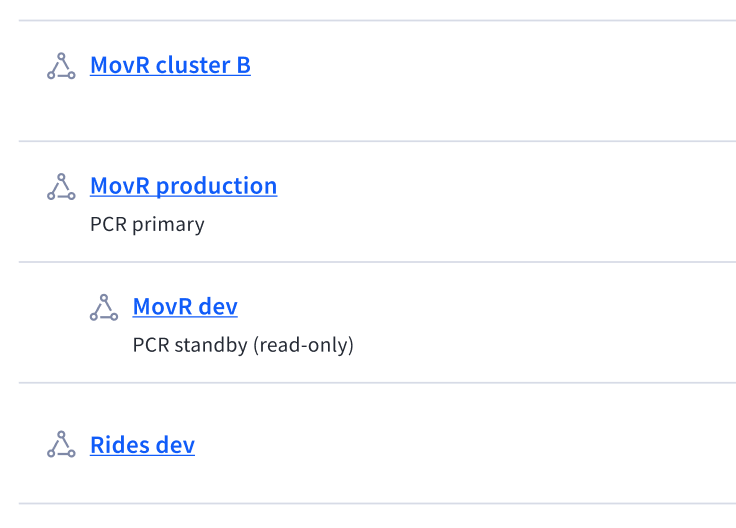
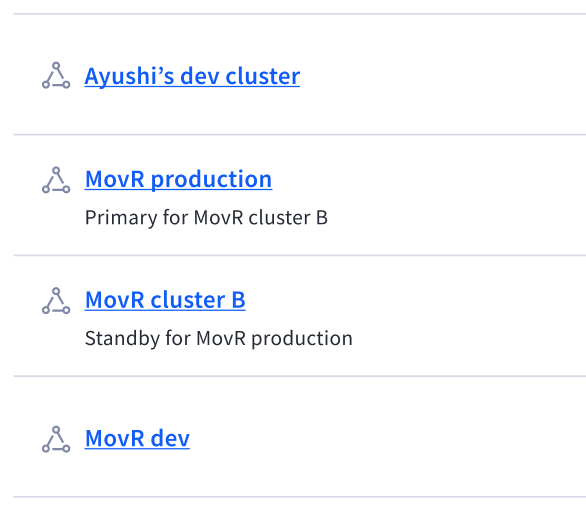
Two of the options I explored to convey the cluster relationship
Independent model for system flexibility
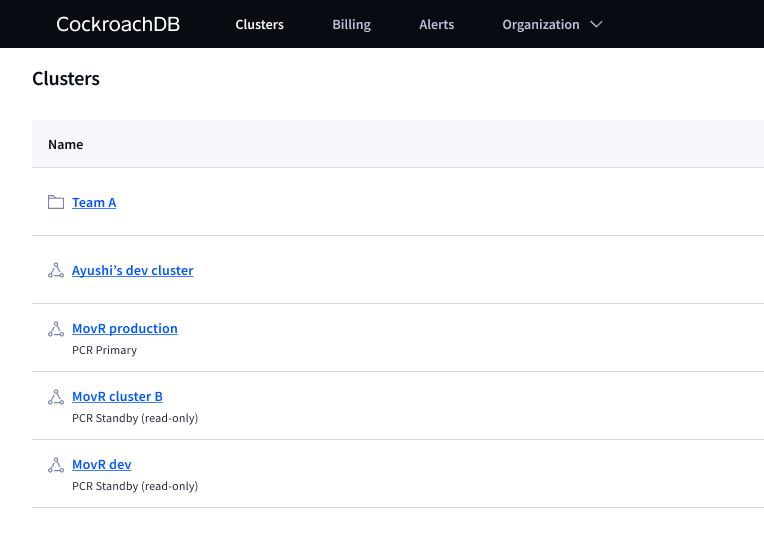
Updating the cluster overview page
Research also exposed a broader issue, the existing Cluster overview page lacked sufficient hierarchy to support complex operational states like PCR. Rather than forcing the feature into an already overloaded framework, I initiated a parallel redesign of the Cluster overview experience. Read about that project in the Cluster health case study.
Redefined the cluster overview page around operational health
Allowing for flexibility
I explored varying degrees of flexibility in the folders, permissions, cluster version, and edit cluster workflows to identify where we needed to enforce constraints and where we could allow for flexibility.
For the cluster version workflow, I enforced constraints to ensure that the Standby cluster’s version is always ahead of the Primary, as required. For all other workflows I included recommendations and tips to avoid limiting adoption while we learn how customers operationalize PCR clusters.
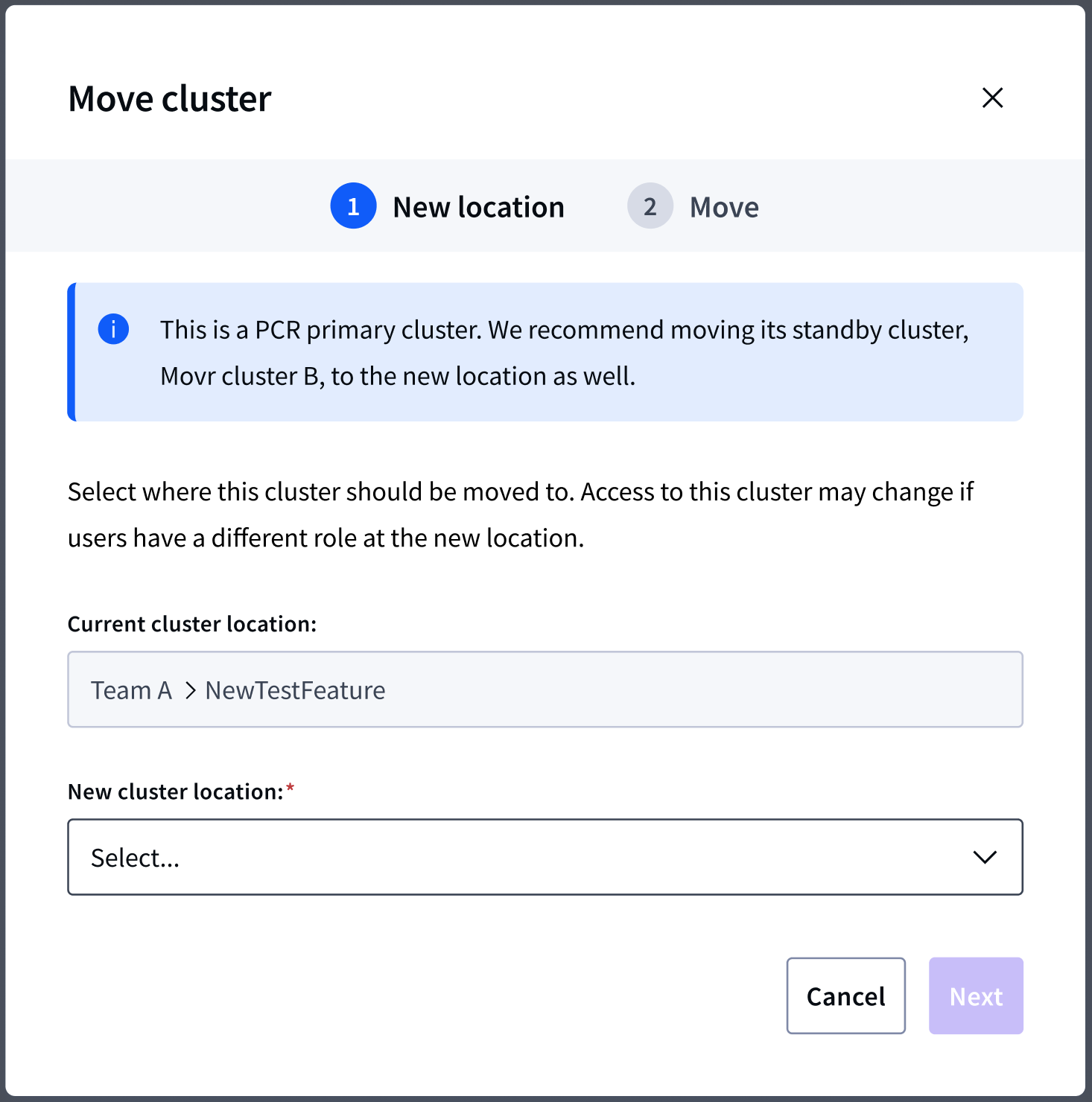
Recommended best practices in the Move cluster workflow
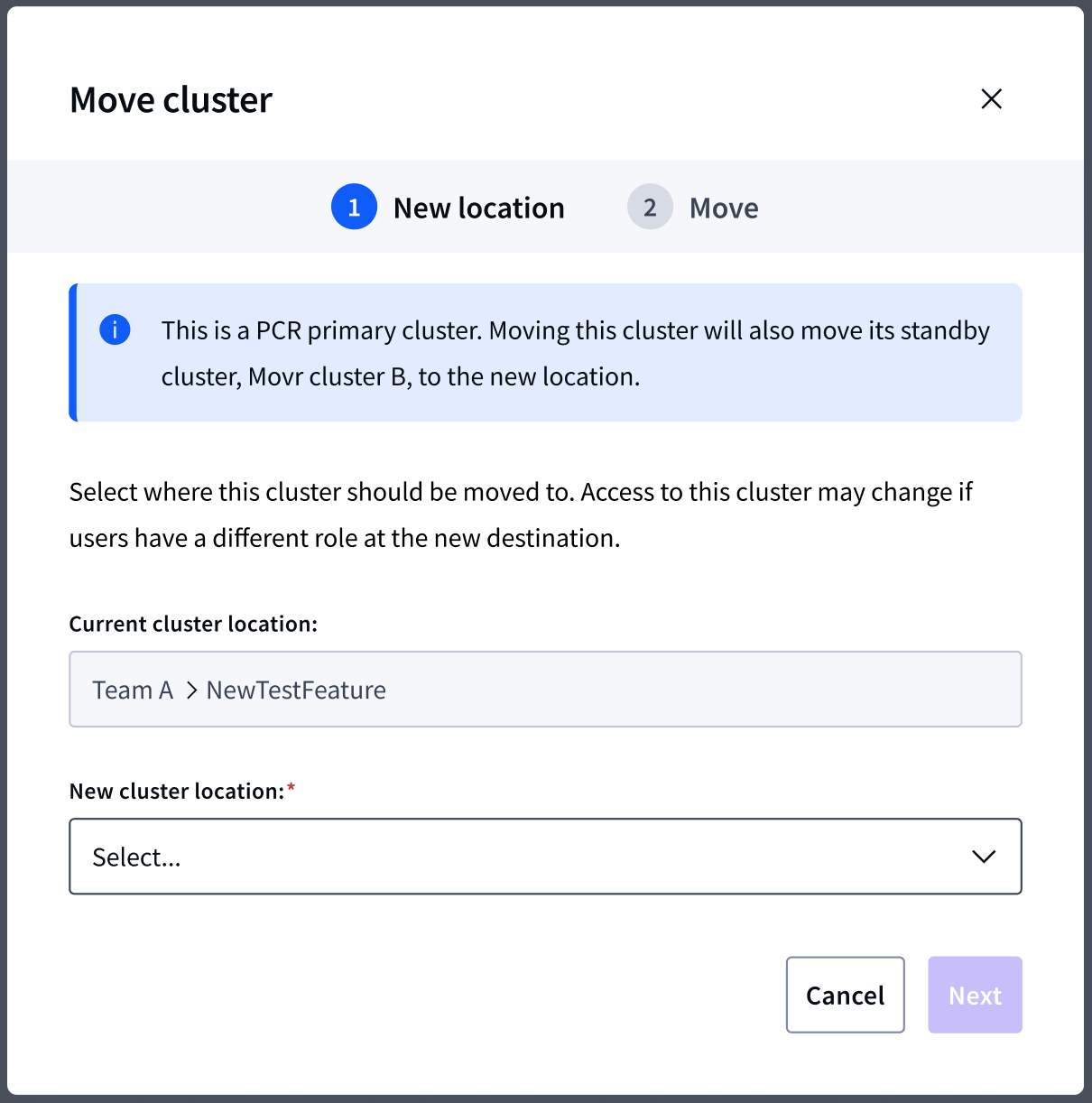
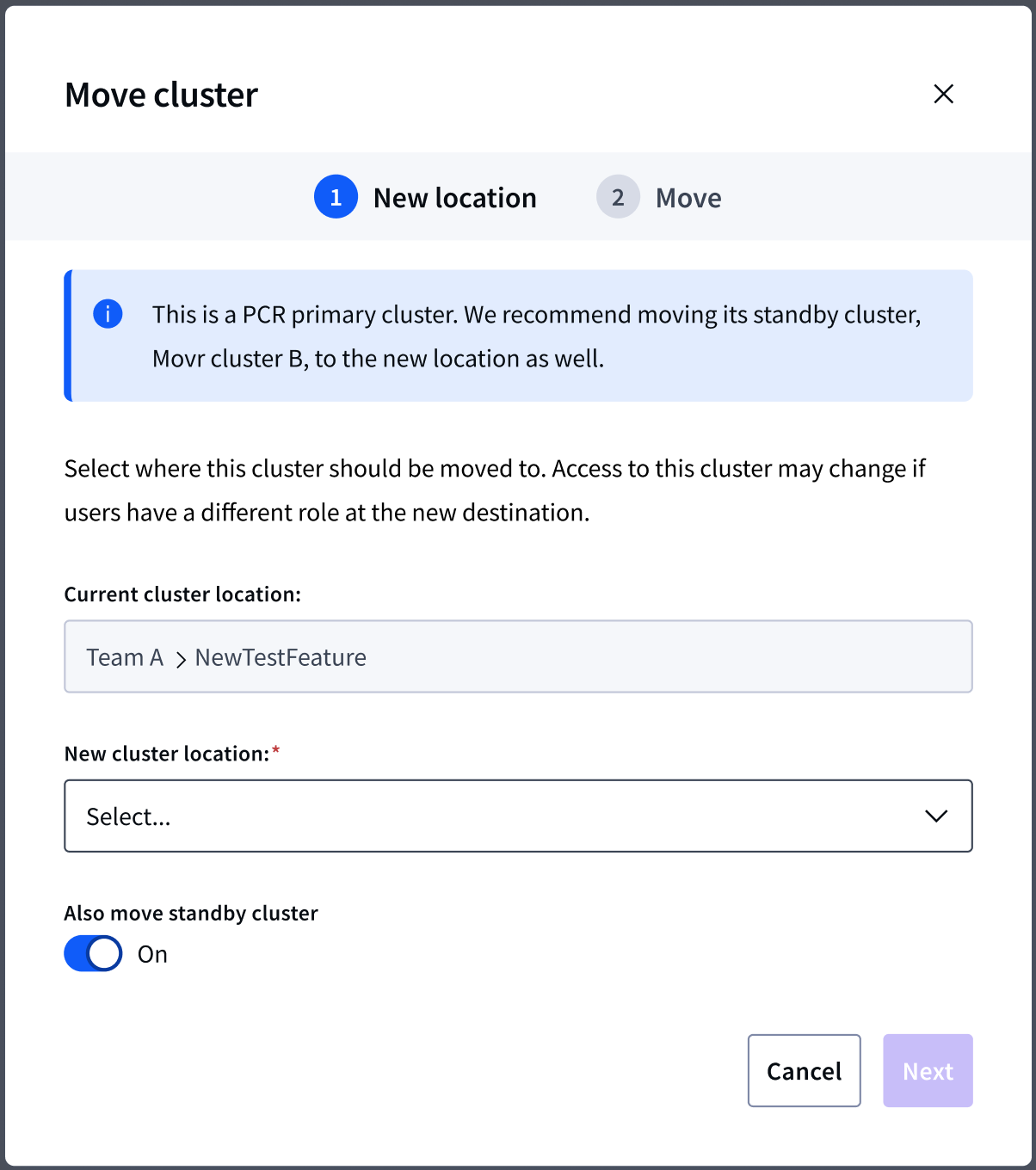
Explored enforcing or facilitating behaviors, but started with recommendations for the first phase
Outcomes
The PCR API shipped and there are currently multiple customers using PCR successfully in production.
Now that this feature is shipped, sales can now win with 2-data-center prospects.
UI explorations led to a better API release with folders and permissions discussions, and with maintenance guardrails added to the API.
PCR work was a direct catalyst for the Cluster overview redesign. Rather than continue to work around a structural problem that the organization had been dealing with for years, I used PCR as the forcing function to address it.
Instrumented trackers to collect usage metrics to inform future phases, such as, replication lag chart views, number of PCR clusters per org, percent of PCR clusters in the same folder, and more.
What I’d do differently
If I were doing this project today, I would incorporate AI earlier in the workflow to accelerate exploration and iteration.
I’d use AI-assisted synthesis to summarize technical documentation, identify workflow edge cases, and rapidly generate early journey maps and relationship models. This would allow me to spend less time constructing foundational artifacts manually and more time validating operational assumptions with Users and stakeholders.
I would also use AI to expand exploratory design work by quickly generating alternative representations of the Primary/Standby relationship and stress-testing workflows through heuristic analysis before User research.
That said, the most critical parts of the project, defining the operational model, identifying the core User confusion around standby behavior, and aligning teams around long-term workflow implications still depended heavily on human judgment, facilitation, and systems thinking.